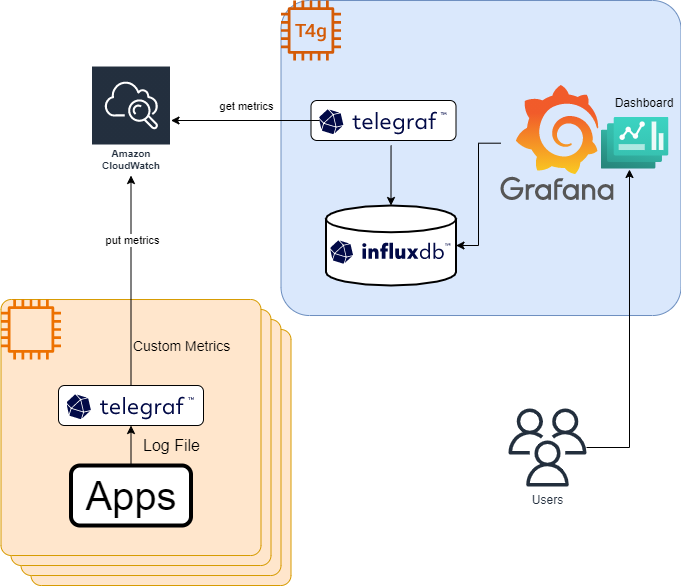
CloudWatchの概念
CloudWatchのデータをブラウザ上で眺めるだけの場合はそこまで気にすることでもないんですが、カスタムメトリクスをCloudWatchに登録したり、CloudWatchのデータをAPIなどで取得する場合には必要な理解についてまとめました。
必須ではない要素は一部省略しているので、それらは公式ドキュメント参照で。
リージョン(region)
シングルリージョン利用の場合はほとんど気にすることがないためか、CloudWatchメトリクスの説明でリージョンが出てくることが少ないです。しかしながら実際はリージョン毎にメトリクスが管理されているため、メトリクス管理の分類では最上位概念といえるかと思います。
当然マルチリージョン環境下では明示的に指定が必要になる要素です。
なお、リージョンAのカスタムメトリクスをリージョンBのCloudWatchに登録することはもちろん可能ですが、リージョンという無駄なディメンションを作ることになるので原則おススメしません。
名前空間(namespaces)
データを分類するための一番大きな単位。アプリケーションやリソースの種類ごとに名前を定義します。
どんな粒度かは、AWS/で始まるAWSデフォルトの名前空間が参考になるかと思います。
メトリクス(metrics)
CloudWatchでの文脈としては「定量化(値に加工)されたデータ」のことを指します。
- 名前(MetricName) : メトリクスの名前
- 値(Value) : データ値
解像度(resolution)と集約(statistics)
値の取得時に指定する項目。CloudWatchには最小で1秒単位のメトリクスが保存されていますが、それらを取得する際には細かすぎる場合があります。
これを1分毎、5分毎といった期間毎の個数や最大値、平均値やパーセンタイルなどの値に集約して取得することができます。
取得した側で集約処理をしなくて良いので使用する側からすると都合がよいです。
ディメンション(dimensions)
メトリクスの固有情報を表したもので、メトリクスの小分類ともいえます。複数定義可能です。
- 名前
- 値
タイムスタンプ
メトリクスの発生した時刻です。
メトリクスのレコード表現
例としてEC2のCPU使用率をこれらの概念で表に表すとこうなります。
| 名前空間 | タイムスタンプ | ディメンション | メトリクス名 | メトリクス値 |
|---|---|---|---|---|
| InstanceId | ||||
| AWS/EC2 | 2023-09-20T01:20:15Z | i-000xxxxxxxxxxxxx1 | CPUUtilization | 0.33000000000000002 |
| AWS/EC2 | 2023-09-20T01:20:15Z | i-000xxxxxxxxxxxxx2 | CPUUtilization | 99.670000000000002 |
このようにして時間やInstanceIdの異なる複数のメトリクスが区別されて管理されています。
ひとりごと
こうしてみるとCloudWatchは監視サービスでありながら、時系列データベースと同じスペックを持ったサービスと捉えることができますね。
Telegraf送信編に続きます(後日執筆)。